word2vec
Tools: Python, TensorFlow, Numpy, Mathplotlib
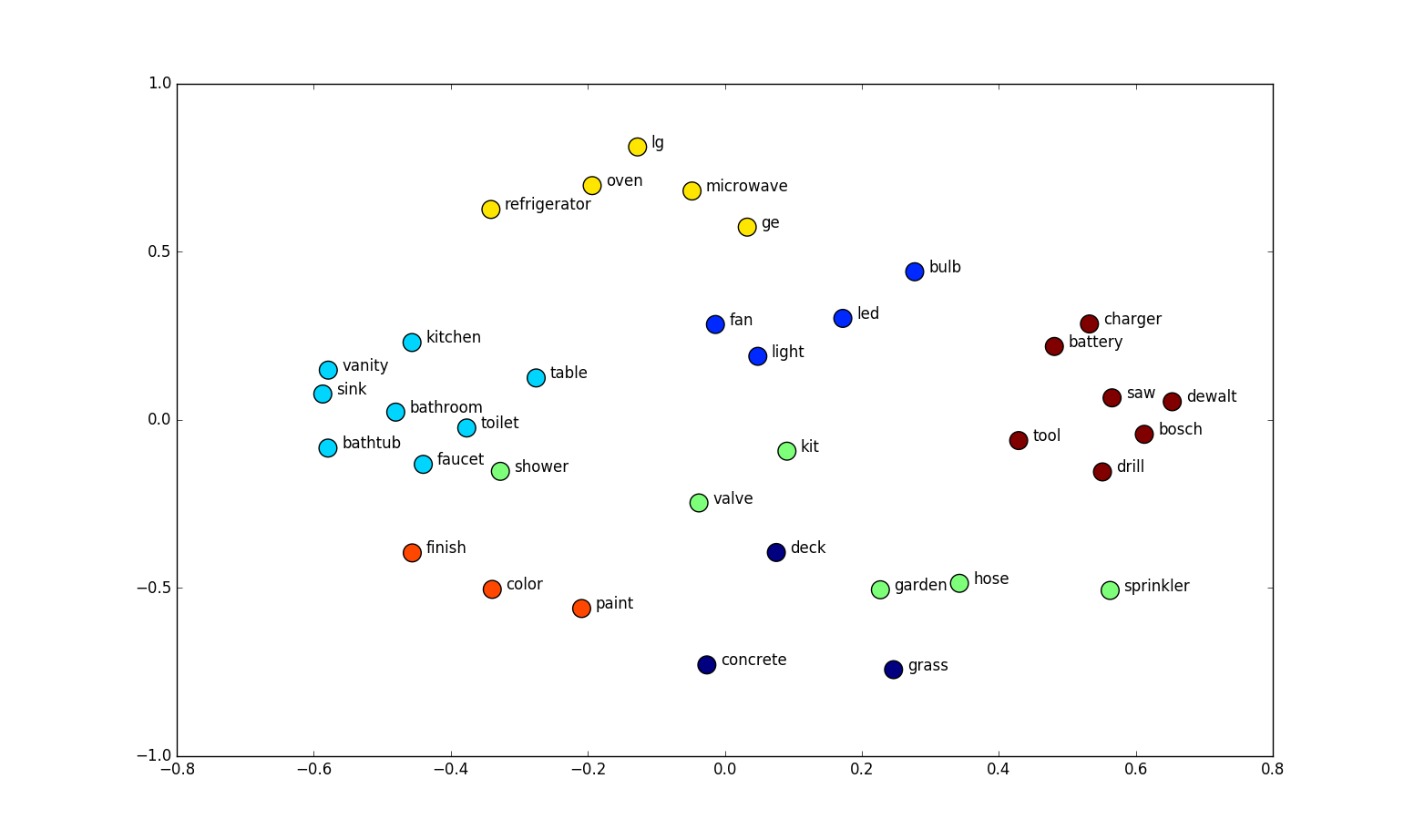
Implements the word2vec skpipgram model. Word2vec takes as its input a large corpus of text and produces a vector space, typically of several hundred dimensions, with each unique word in the corpus being assigned a corresponding vector in the space. Word vectors are positioned in the vector space such that words that share common contexts in the corpus are located in close proximity to one another in the space. Run the file by typing
python wordvec.py
There are 3 languages currently supported, English, French, and Korean. The output generated includes a sample of words with the top 8 semantically nearest words, in "output.txt". As well, a 2-dimensional graph visualizing the semantic relationship between words is produced in "tsne.png".